I'm Vitalii Barenin. I live, work, and study across Moscow, Ryazan, and Tver, focusing on backend development and network infrastructure design.
Some facts about me and my career:
Education — Graduated with honors from Ryazan State Radio Engineering University (named after V.F. Utkin) with a B.Sc. and M.Sc. in Computer Science and Engineering. Currently pursuing a Ph.D. in Information Technology and Telecommunications.
Backend Development — Experienced with Python, Django, FastAPI, PostgreSQL, MongoDB, RabbitMQ, Redis, Celery, Docker. Built systems for asset management, document workflows, and network infrastructure monitoring.
Network Engineering — Hands-on experience with telecommunication equipment (LAN, MAN), as well as designing and deploying network infrastructure.
Open Source — Contribute to solving issues in open source projects, experiment with new technologies, and share my code on GitHub.
I enjoy continuous growth and moving forward, expanding my knowledge and perspective on the world.
Education
- Institution
- Ryazan State Radio Engineering University
- Date
- — Present
- Degree
- Ph.D. in Information and Communication Technology
- Institution
- Ryazan State Radio Engineering University
- Date
- —
- Degree
- M.Sc. in Computer Science and Engineering
- Institution
- Ryazan State Radio Engineering University
- Date
- —
- Degree
- B.Sc. in Computer Science and Engineering
Experience

- Company
- Administration of Special Communications and InformationTver
- Role
- Engineer
Since 2020, I have been administering distributed local area networks consisting of switches and routers (Cisco, D-Link, etc.), Aquarius servers, firewalls, and other telecommunications equipment. I designed the architecture and developed working documentation for network access nodes.
As part of automating engineering staff workflows, I developed a unified system for network management and monitoring, tailored to the organization’s internal needs.

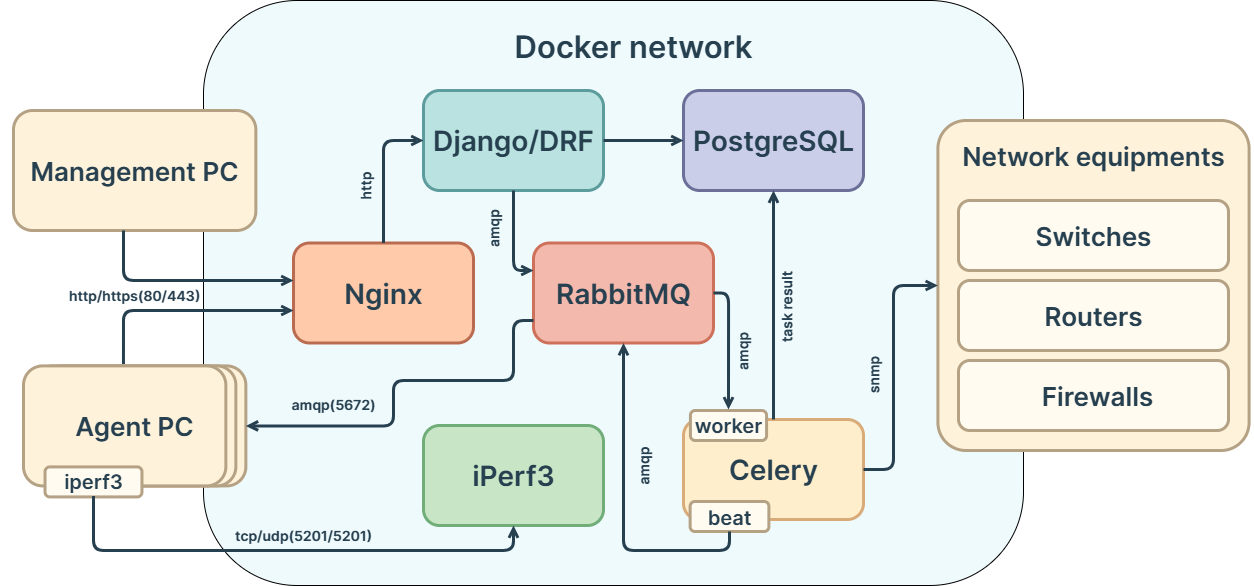
The main goals were: accelerating the localization of problematic segments and creating a unified diagnostic client for the decentralized network.
The service is a comprehensive network monitoring and diagnostic solution, deployed on a single physical server in a Docker environment.
- Nginx — receives HTTP/HTTPS requests from users and proxies them to Django.
- Django + DRF — central API and web interface, responsible for task management and result collection.
- RabbitMQ — message broker through which:
- Django sends tasks to agents.
- Celery worker receives tasks for equipment polling.
- Celery + Celery Beat — task scheduler and executor:
- Beat schedules SNMP polling tasks for equipment.
- Worker performs polling and stores results in the database.
- PostgreSQL — stores inventory, tasks, test results, and logs.
- iPerf3 — service for active bandwidth testing.
- Agents (Python service) — installed on client PCs, receive tasks via RabbitMQ, run tests (ping, iperf3), and send results back to Django (HTTP callback).
- Network equipment — polled by the Celery worker via SNMP and remotely managed (read/modify configurations).
As a result:
- Reduced time for diagnostics and problem localization (MTTR↓).
- Enabled remote diagnostics from the client side (ping/iperf3).
- Delivered a unified web interface for incidents, logs, and test results.
Since 2023, under an outstaffing model, I have been regularly engaged in projects of TsOI "Energia" as a backend developer. In addition to numerous tasks related to enhancements and modifications of existing services for multifunctional centers of the Moscow region (adding and modifying REST endpoints (DRF), adjusting business logic, extending data models, refining serializers and their validations, integrating with external APIs), I participated in two major internal projects of the organization:
- Asset management service for fixed assets in operational departments, aimed at supporting and planning organizational and technical activities (maintenance, write-offs, etc.).
- Internal document management information system, which evolved from the "Official Legal Information Internet Portal".
Key tasks within the projects included:
- Designing and implementing the domain model (accounting of fixed assets and materials).
- Developing REST API (DRF) for CRUD operations and business processes (acceptance, transfer, write-off).
- Working with transactions in PostgreSQL (
transaction.atomic(),select_for_update(),on_commit()) to ensure data integrity and concurrency safety. - Storing and reproducing document operations in MongoDB (context snapshots).
- Automatic document generation (PDF/DOCX) based on versioned templates (Jinja2,
wkhtmltopdf/WeasyPrint). - Setting up reminders and background tasks with Celery Beat (brokers: Redis → RabbitMQ).

- Company
- Open Source
- Role
- Contributor
Contributed to the development of the open source project GitIngest.

Main tasks:
- Developed and refined Git logic on Windows, ensuring stable cross-platform behavior.
- Implemented and extended REST API using FastAPI + Pydantic (validation, schemas, typing).
- Participated in configuring CI/CD (GitHub Actions), improving build reliability and test coverage.
- Set up pre-commit hooks for code quality control, including:
ruff(linter and formatter),pylintandisort,pyupgrade,markdownlint,eslintfor JavaScript,- security checks with
gitleaks.
Based on Tailwind UI, developed a personal resume website coders-cv, where I presented my experience and projects in an interactive and user-friendly format.

Main tasks:
- Used Next.js + React to build the site structure and Tailwind CSS for fast, responsive design.
- Added dark mode, animations, and SEO optimization to make the site professional and modern.
- Integrated components (experience cards, timelines, links to projects and GitHub) inspired by Tailwind UI and adapted them to my personal data.

- Company
- EPAM SystemsRyazan
- Role
- Junior .NET Developer
- Development and maintenance of enterprise applications using C# / ASP.NET.
- Implementation of business logic and integration with external systems.
- Working with databases (MS SQL Server, Entity Framework), query optimization.
- Writing unit and integration tests (xUnit, NUnit, Moq), bug fixing, debugging.
- Participation in team development using Agile (Scrum), conducting code reviews.